FinBERT Research Project - NLP
Training & Fine-Tuning 11 machine learning models for performance evaluation of a Large Language Model that adapts to financial texts - FinBERT
Music Flip: Computer Vision Android App - CV/Android
Developing an Android application that uses Computer Vision to help users flip sheet music with head gesture
Sentiment Analysis - Machine Learning
Training 1-Layer Perceptron, CNN, RNN, and RNN+CNN models for sentiment analysis to rank the attitude of input text data!
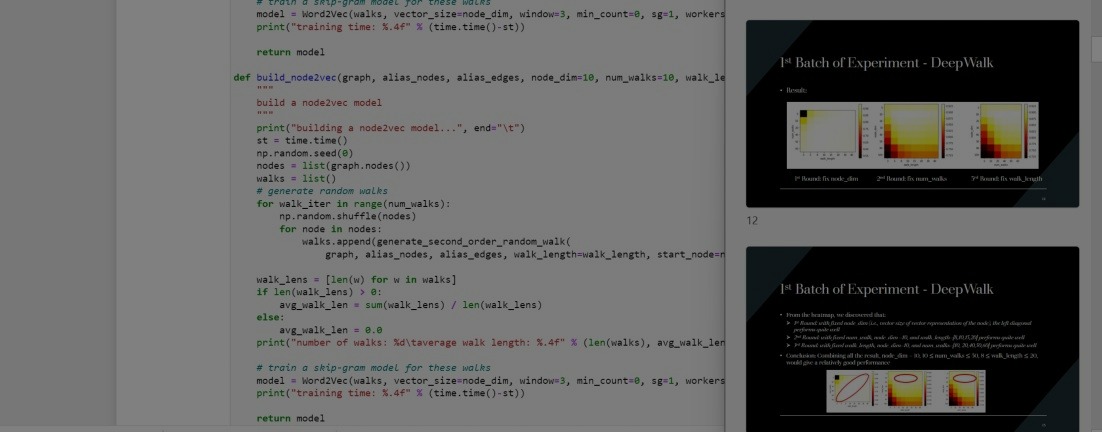
Social Network Mining - Machine Learning
Training and tuning DeepWalk & Node2Vec models for social network mining to do link prediction given 2 users!
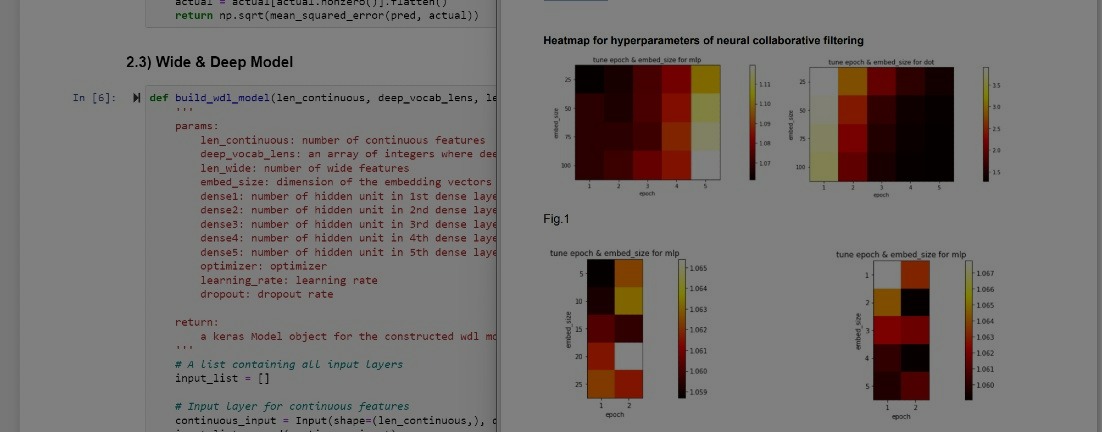
Rating Prediction - Machine Learning
Training and tuning Neural Collaborative Filtering & Wide and Deep Learning models to do predictions for user ratings on items!
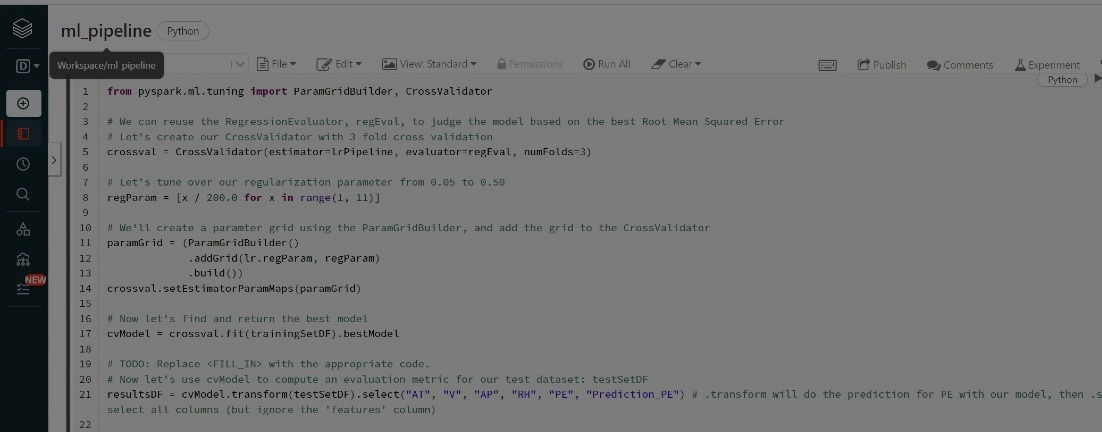
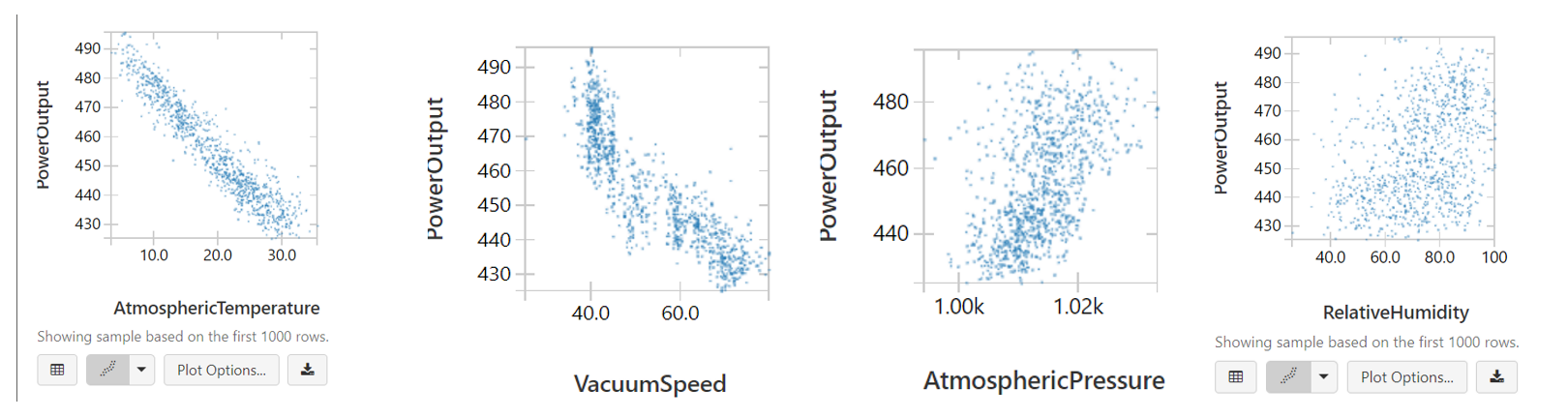
Power Plant Machine Learning Pipeline - Spark
Explore data & training and tuning Linear Regression, Decision Tree Regression, and Random Forest Tree models for predicting power output!
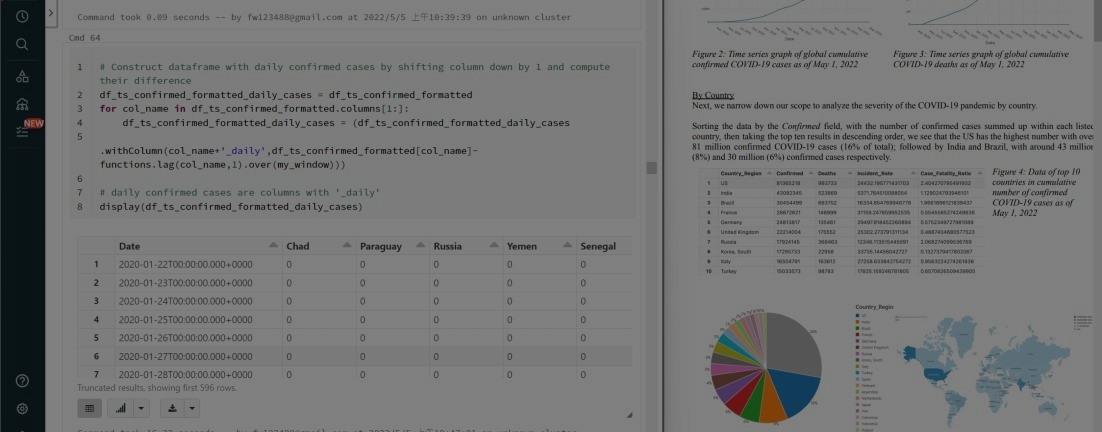
COVID-19 Big Data Analysis - PySpark
Using Pyspark to perform big data analysis with Databricks on world COVID-19 data to gain insights on current pandemic situations!
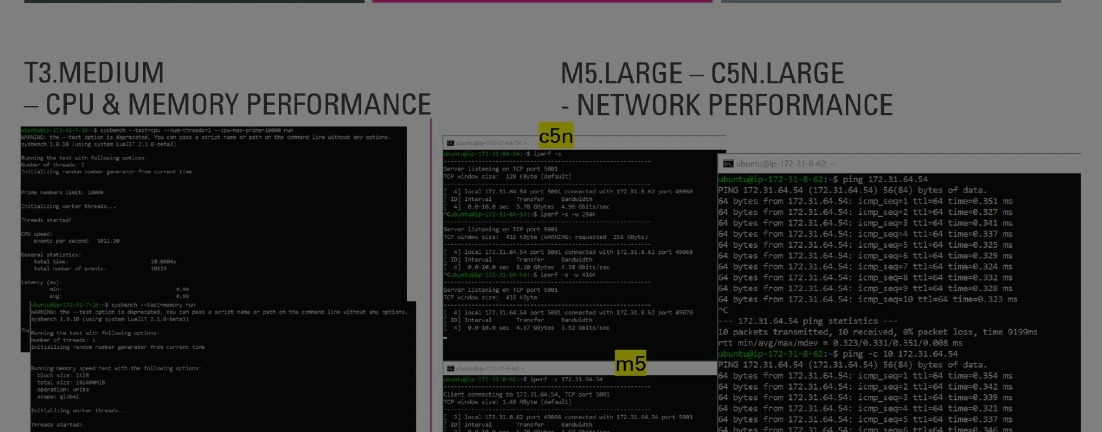
AWS EC2 Measurement
Measuring CPU, memory, and network performances of different AWS EC2 instances!
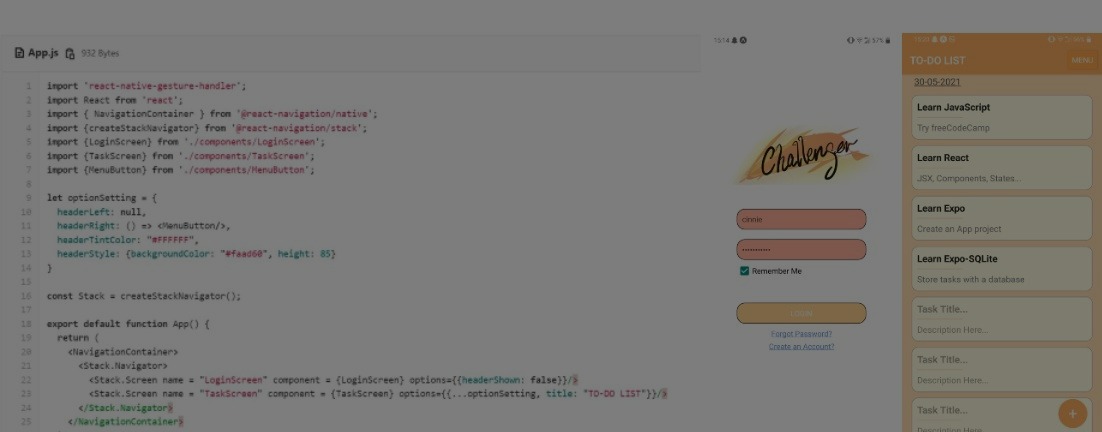
Challenger - Task Tracking Mobile Application
Creating my first mobile app with JavaScript, React/React Native, Expo, and SQLite during the mentorship program organized by Credit Suisse!
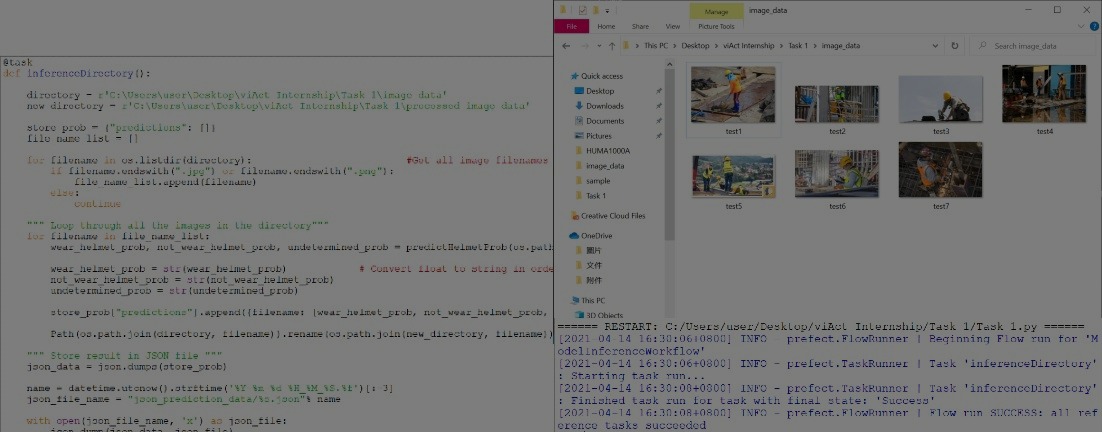
Model Inference Workflow
Using Python with the Prefect Library to create a model inference workflow to store AI model results in a local directory during my internship in viAct.ai!
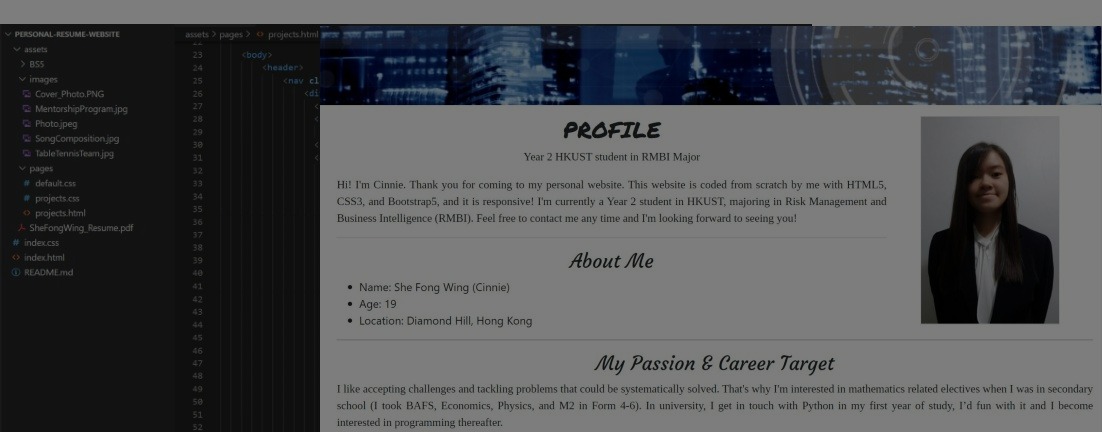
Personal Resume Website
Self-initiated project using self-learnt HTML5, CSS3, JS and Bootstrap5 to create my own responsive webesite!
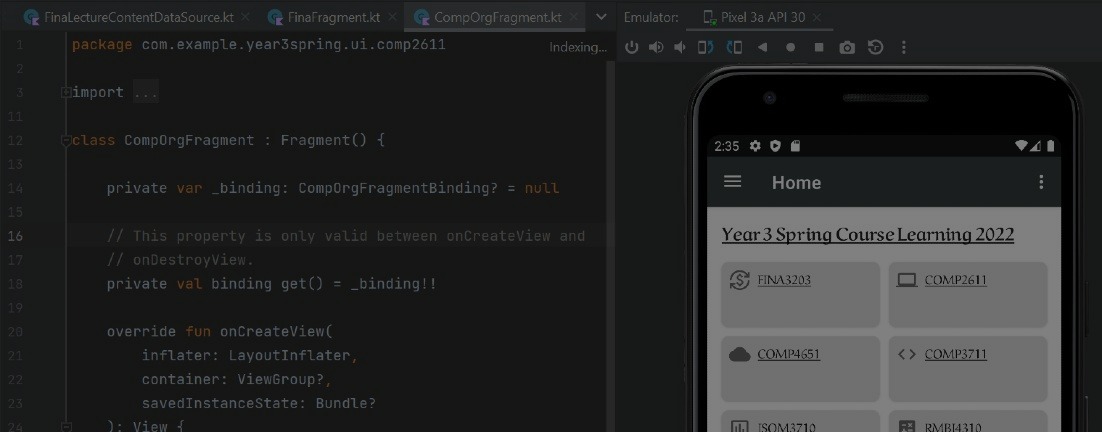
Course Learning 2022 App - Android
Self learnt the basics of Kotlin with Android Studio to create a mobile app for my course notes!
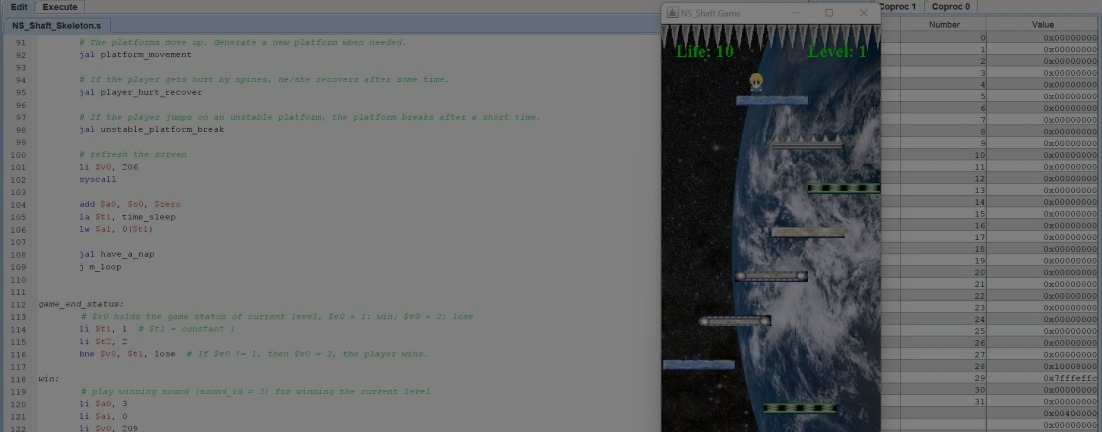
NS-Shaft game - MIPS
Using MIPS assembly language to construct the NS-Shaft game with MARS!
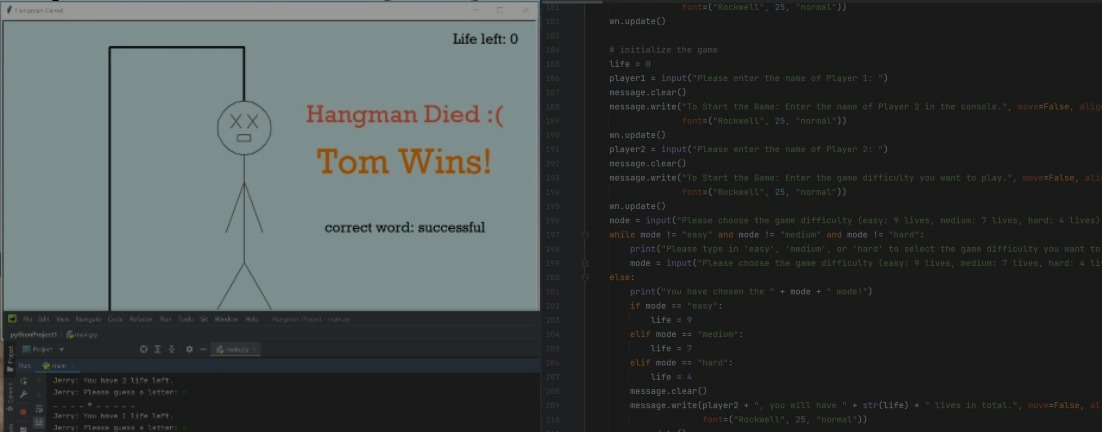
Hangman Project
Using Python to write a hangman game from scratch in the FDM Group Women in Tech Bootcamp!